Exploring the KITTI road dataset
Background
The Kitti road dataset is an image dataset that is used for training and evaluating models on the semantic segmentation task (labeling every single pixel in an image as belonging to one of many possible classes).
This post will make sense of the dataset that is labeled as base kit with: left color images, calibration and training labels (0.5 GB),
which can be downloaded with this link
Exploring the directory structure
Once you have downloaded the data and unzipped it, the data will contain the following directory structure
data_road
testing
calib
umm_000040.txt
um_000006.txt
uu_000030.txt
...
image_2
umm_000042.png
uu_000023.png
um_000019.png
...
training
calib
'umm_000040.txt',
'um_000006.txt',
'umm_000022.txt'
...
gt_image_2
umm_road_000042.png
um_lane_000019.png
um_road_000019.png
uu_road_000064.png
...
image_2
umm_000042.png
um_000019.png
uu_000064.png
...
Of particular importance for training a model to perform semantic segmentation are
the following subdirectories of the training directory:
image_2: The RGB training images we want to use as inputgt_image_2: Contains the ground-truth images (labels) as RGB images of same dimensions as the training images, but color coded to show segmentation labels.
You will notice that the files in the labels directory contain slightly different naming convention from the input images. The files contain either road or lane in the filename. This is because there are labels for the entire road, as well as labels for the
current lane that the car is on.
Exploring the training and label files
We can start by setting up the path variables.
import os import glob # Directories root_data_dir = "/path/to/data_road" imgs_dir = os.path.join(root_data_dir, "training/image_2") labels_dir = os.path.join(root_data_dir, "training/gt_image_2") def dirfiles(d, pattern="*"): """ Gets the filepaths in a directory that match some pattern""" return glob.glob(os.path.join(d, pattern)) img_files = dirfiles(imgs_dir, "*.png") label_files = dirfiles(labels_dir, "*.png")
When we compare the number of png files in the two directories we see that
there is a mismatch. There are less training images than label images.
print(len(img_files)) # 289 print(len(label_files)) # 384
This is because there are no lane labels for all the training images, only the
subset of images that start with um. There is, however, a 1:1 mapping between
all training images and the labels for the road. If we filter for just the
road labels we see that the number of images are the same.
road_label_files = [file for file in label_files if "road" in os.path.basename(file)] len(road_label_files) # 289 len(img_files) # 289
Since the difference in the filenames is just the addition of _road_, we
can prove to ourselves that there is indeed a 1:1 mapping of the file names
in each directory.
# Sort the filepaths img_files.sort() road_label_files.sort() # Filenames without exensions a = list(map(lambda f: os.path.basename(f), img_files)) b = list(map(lambda f: os.path.basename(f.replace("_road_","_")), road_label_files)) # Check how many have same filename n_same = sum(list(map(lambda ab: ab[0] == ab[1], zip(a,b)))) print(n_same) # 289
We see that the number of files whose name matches up is equal to the number of files, meaning all the file names match up.
Exploring the Images
We can have a look at the images and label images. You will notice that the images are quite big, 1242 by 375 pixels.
import PIL as pil from PIL import Image i = 111 img = pil.Image.open(img_files[i]) print("IMAGE DIMS: ", img.size) # IMAGE DIMS: (1242, 375)
# Training image img.show()

# Label image label = pil.Image.open(road_label_files[i]) label.show()

# Overlay label image on top of train image overlay = pil.ImageChops.add(img, label, scale=1.5) overlay.show()

Understanding the label representation
We saw that the labeled pixels were only one of three colors:
- magenta : Road
- red : Not road
- blank : For some reason, also road. Usually road that is on the other side of a traffic island.
You will notice that the label colors are not Red, Green, Blue. Which means that the class labels are not one-hot encoded along the channels axis.
Converting pixels to one-hot-vectors
We can transform this so that each color channel represents a different class. This way, every single pixel is one becomes a one hot vector that can be classified using Softmax.
import numpy as np label_array = np.asarray(label) # Current class label encoding non_road_label = np.array([255,0,0]) road_label = np.array([255,0,255]) other_road_label = np.array([0,0,0]) # Create a one hot encoded version of the label image ohv_label = np.zeros_like(label_array) ohv_label[:,:,0] = np.all(label_array==road_label, axis=2).astype(np.uint8) ohv_label[:,:,1] = np.all(label_array==other_road_label, axis=2).astype(np.uint8) ohv_label[:,:,2] = np.all(label_array==non_road_label, axis=2).astype(np.uint8)
We can now view the label image, which should have all classes as either red, green or blue.
pil.Image.fromarray(ohv_label*255).show()
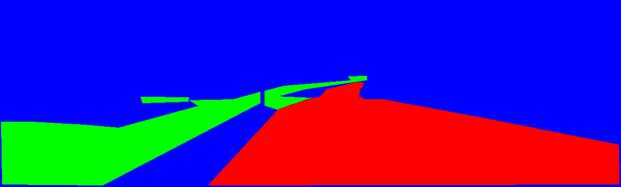
Converting pixels to binary classes
However, if we are just interested in the binary classification task of road/not road for each pixel, then we can take the non-road mask, and invert it to only capture the roads. This will allow us to store the label in a single color channel.
# Current class label encoding non_road_label = np.array([255,0,0]) # Create binary class label (1=road, 0=not road) by inverting non-road label binary_label = (1-np.all(label_array==non_road_label, axis=2)).astype(np.uint8)
We can now view this mask:
# Binary label image binary_label_img = pil.Image.fromarray(binary_label*255) binary_label_img.show()

And overlayed on the original image:
# Overlay label image on top of train image overlay_binary = pil.ImageChops.add(img, binary_label_img.convert("RGB"), scale=1.7) overlay_binary.show()

Full code to go from image file to binary encoded label image
Putting together all the relevant code to go from the directory storing your data to creating binary classification segmentation label images looks like the following. The only slight changes I made were that I filtered out lane label images right away with a different regex pattern. The other minor difference is that I loaded the images directly to numpy arrays using scipy instead of using PIL. PIL was useful for viewing the images, but now we can avoid those steps and use numpy directly.
import os import glob import scipy from scipy import misc # Directories root_data_dir = "/path/to/data_road" # imgs_dir = os.path.join(root_data_dir, "training/image_2") labels_dir = os.path.join(root_data_dir, "training/gt_image_2") # Only get the labels for road (not lane) label_files = glob.glob(os.path.join(labels_dir, "*_road_*.png")) i = 111 # index of image (perhaps use a for loop to iterate through all) label_array = scipy.misc.imread(label_files[i]) # Current class label encoding non_road_class = np.array([255,0,0]) # Create binary class label (1=road, 0=not road) by inverting non-road label binary_label = (1-np.all(label_array==non_road_class, axis=2)).astype(np.uint8)
Final remarks
Hopefully this will help someone in making sense of the KITTI road dataset.
Appendix - Code used to save images
# SAVE IMAGES resize = (621, 187) img.resize(resize, Image.ANTIALIAS).save("train_image.jpg", format="JPEG") label.resize(resize, Image.ANTIALIAS).save("label_image.jpg", format="JPEG") overlay.resize(resize, Image.ANTIALIAS).save("overlay_image.jpg", format="JPEG") pil.Image.fromarray(ohv_label*255).resize(resize, Image.ANTIALIAS).save("ohv_label.jpg", format="JPEG") binary_label_img.resize(resize, Image.ANTIALIAS).save("binary_label.jpg", format="JPEG") overlay_binary.resize(resize, Image.ANTIALIAS).save("overlay_binary.jpg", format="JPEG")
Comments
Note you can comment without any login by:
- Typing your comment
- Selecting "sign up with Disqus"
- Then checking "I'd rather post as a guest"