General Structure
The general structure that is used by most of the deep neural network models for semantic segmentation is similar to the one illustrated in the diagram below. The architecture goes through a series of downsampling layers that reduce the dimensionality along the spatial dimensions. This is then followed by a series of upsampling layers that again increase the dimensionality along the spatial dimensions. The output layer has the same spatial dimensions as the original input image.
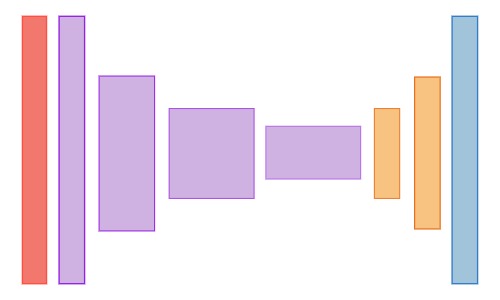
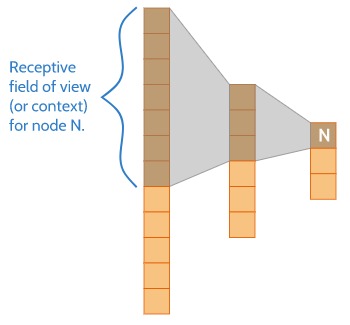
The idea behind why this works is as follows. During the downsampling process, the model gains more and more information about what is going on in bigger regions of the image. The diagram below gives you a visual intuition of this. As the model gains a bigger context of the image, it becomes more capable of understanding what is going on in the scene. This is part of why deep convolutional neural networks are so effective for classification tasks. But, as it gains more information about the overall scene during the downsampling process, it also starts to lose spatial information. The fine details about the locations of things in the image start to be lost.
For segmentation tasks, we wish to preserve both forms of information. We wish to preserve the information that would make a good classifier, so the model can recognize the difference between a dog, a cat, a car, or whatever other things we are interested in. But we also want to preserve the very fine details about the locations of these things. For this reason, it is quite common for segmentation models to pass some information from earlier layers directly into the upsampling layers. The diagram below illustrates this idea.
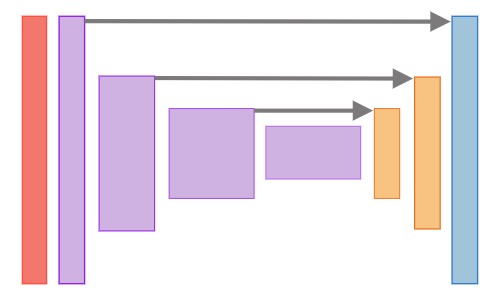
The information that is passed, as well as how it is combined, differs quite a bit for different architectures. In some architectures, the entire output features at that layer get passed along. These get combined with later layers through elementwise addition. In other architectures, such as Segnet, only the indices of the elements that were kept during the max-pool operation are passed along. These are then used to reverse the max-pooling operation, using the same indices.
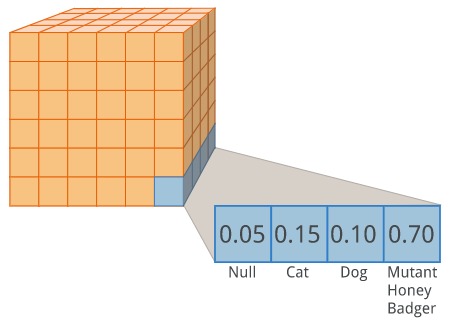
The purpose of the upsampling portion of the architecture is so that we end up with an output that has the same spatial dimensions as the original input image. The idea, is after all, to label every single pixel. The number of channels on the output layer, however, will differ from the input image. The number of channels will be dependent on how many classes of objects we wish to identify.
At this point, you might get an AHA! moment. Semantic segmentation is actually just a classification task. We are performing a classification for every single pixel in the image. Does this pixel belong to a cat? a dog? a mutant honey badger?
The way that upsampling is performed also differs for different architectures. Many architectures use something called a transpose convolution (sometimes called a fractionally-strided convolution, and sometimes incorrectly referred to as a de-convolution). It can be thought of as a convolutional layer, that makes the feature-map bigger, rather than smaller when you adjust the step size.
Another popular technique for upsampling, which was introduced by Badrinarayanan et al (2015), is to use a max un-pooling operation. It takes the indices from a corresponding max-pooling operation during the downsampling process and uses those indices place the value to be upsampled in the same spatial position which contained the max value in the down-sampling operation. This allows the model to preserve some of that fine-grained spatial information we want, without adding any computationally expensive learnable parameters.